Tìm hiểu công ty Logstash nhập khối hệ thống ELK Stack Logging – Cuongquach.com | Tại nội dung bài viết này tất cả chúng ta sẽ không còn cút cụ thể về kiểu cách thiết đặt Logstash và cơ hội thông số kỹ thuật Logstash xử lý những sự kiện log được trao kể từ những mối cung cấp log gửi cho tới. Mà chỉ trải qua tổng quan tiền về sinh hoạt và cấu tạo Logstash, một công ty cần thiết nhập khối hệ thống ELK Stack cho tới sinh hoạt quản lý và vận hành log triệu tập. (Bài viết lách trực thuộc Series về ELK Stack Logging)

Bạn đang xem: logstash la gi
Có thể chúng ta quan hoài chủ thể khác
– Lộ trình nghiên cứu và phân tích học tập DevOps/Frontend/Backend 2018
– Top chứng từ Linux quốc tế tuy nhiên Quản trị viên nên có
– Các mẹo tăng vận tốc thực đua bên trên Ansible
1. Logstash là gì ?
Trang chủ: https://www.elastic.co/products/logstash
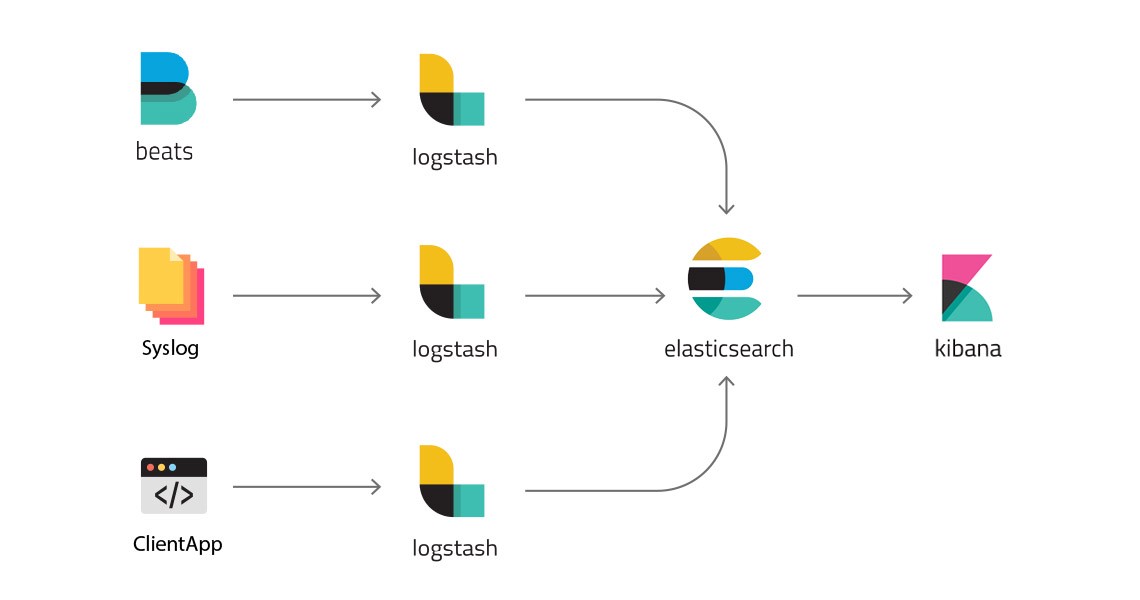
Logstash là một trong lịch trình mã mối cung cấp hé, trực thuộc hệ sinh thái xanh của cục thành phầm ELK Stack, với trách nhiệm rất rất cần thiết bao hàm thân phụ tiến độ nhập chuỗi xử lý sự khiếu nại log (pipeline) ứng thân phụ module:
- INPUT: tiếp nhận/thu thập tài liệu sự khiếu nại log ở dạng thô kể từ những mối cung cấp không giống nhau như tệp tin, redis, rabbitmq, beats, syslog,….
- FILTER: Sau Khi tiêu thụ tài liệu tiếp tục tổ chức thao tác tài liệu sự khiếu nại log (như tăng, xoá, thay cho thế,.. nội dung log) theo đuổi thông số kỹ thuật của cai quản trị viên nhằm xây đắp lại cấu tạo tài liệu log sự kiện theo đuổi ước muốn.
- OUTPUT: Sau nằm trong tiếp tục triển khai gửi tiếp tài liệu sự khiếu nại log về những công ty khác ví như Elasticsearch tiêu thụ tàng trữ log hoặc hiển thị log,..
2. Workflow xử lý pipeline
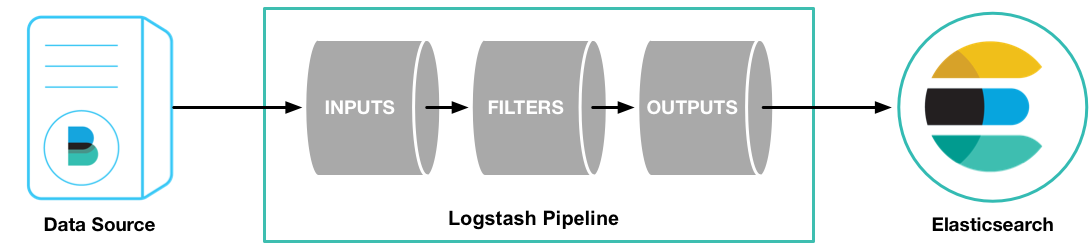
Ở bước INPUT, Logstash sẽ tiến hành thông số kỹ thuật lựa lựa chọn kiểu dáng tiêu thụ log sự kiện hoặc là di chuyển lấy tài liệu log ở dịch remote theo đuổi nhu yếu. Sau Khi lấy được log sự kiện thì , mạng INPUT tiếp tục ghi tài liệu sự kiện xuống sản phẩm đợi triệu tập ở bộ nhớ lưu trữ RAM hoặc bên trên ổ cứng.
Mỗi pipeline worker thread tiếp tục nối tiếp lấy hàng loạt sự khiếu nại đang trong sản phẩm đợi này nhằm xử lý FILTER giúp tái mét cấu tạo tài liệu log sẽ tiến hành gửi cút tại đoạn OUTPUT. Số lượng sự khiếu nại được xử lý hàng loạt và con số pipeline worker thread rất có thể được thông số kỹ thuật tinh ma chỉnh tối ưu rộng lớn, nội dung này rất có thể kể tại đoạn không giống.
Mặc quyết định Logstash dùng sản phẩm đợi trực thuộc bộ nhớ lưu trữ RAM trong số những tiến độ (input -> filter và filter -> output) nhằm thực hiện cỗ đệm tàng trữ tài liệu sự kiện trước lúc xử lý. Nếu tuy nhiên lịch trình công ty Logstash của chúng ta vì như thế một nguyên nhân nào là bại bị ngừng sinh hoạt thân thích chừng, thì những tài liệu sự kiện đang trong buffer có khả năng sẽ bị rơi rụng.
Input
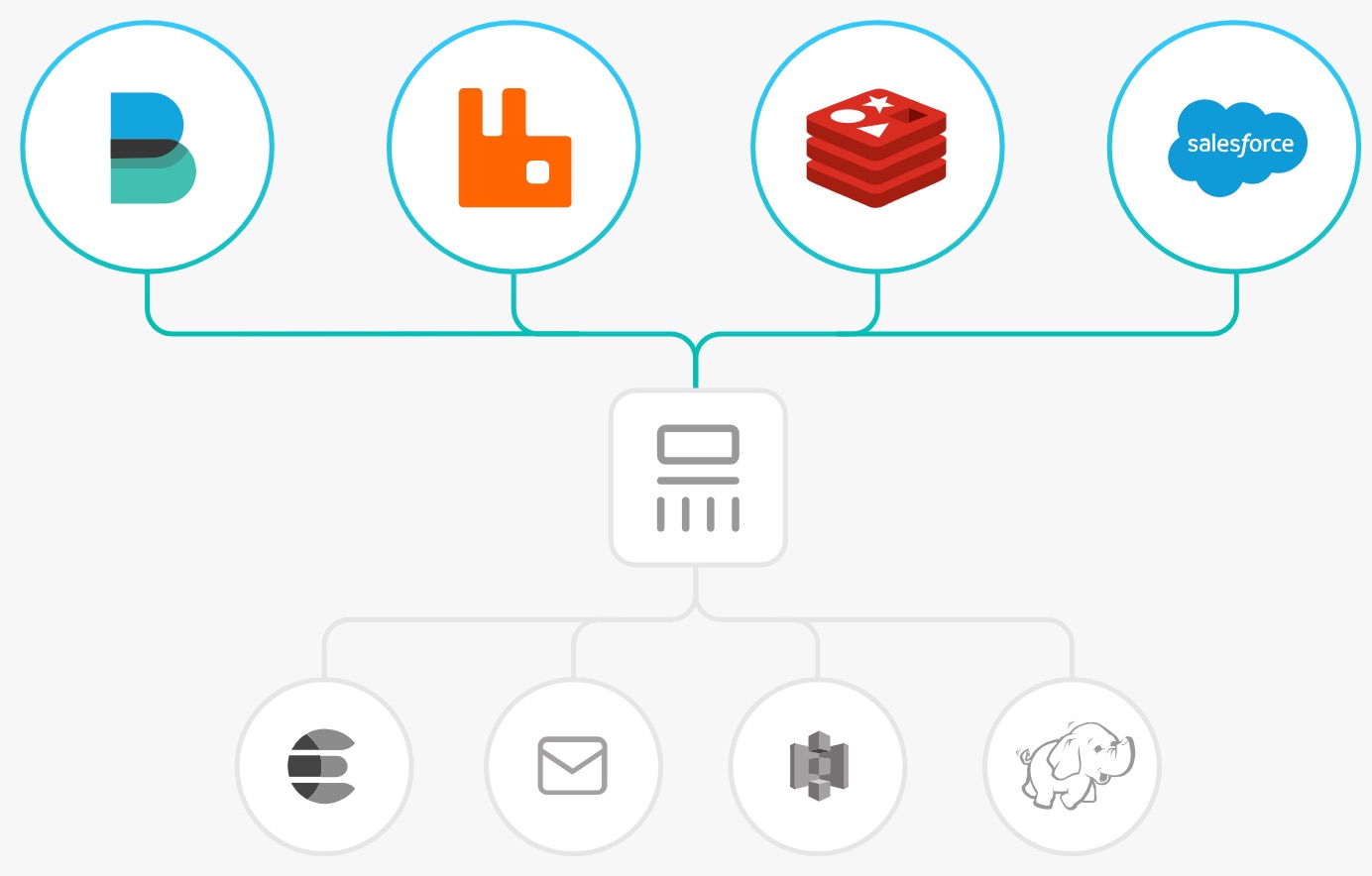
Bạn tiếp tục dùng phần thông số kỹ thuật block ‘INPUT’ nhằm quy quyết định chế độ nhận/lấy log nhập lịch trình Logstash. Một số Input plugin thông dụng thông thường được dùng nhằm nhận/lấy log như :
- file: hiểu tài liệu kể từ tệp tin bên trên filesystem, tương tự mệnh lệnh ‘tail -f’ bên trên UNIX.
- syslog: lịch trình Logstash tiếp tục lắng tai bên trên port 514 nhằm tiêu thụ tài liệu syslog.
- redis: hiểu tài liệu log kể từ redis server, dùng cả hai chế độ redis channel và redis lists.
- beats: xử lý những tài liệu vấn đề được gửi kể từ lịch trình Beats (một thành phầm phổ biến nhập khối hệ thống ELK)
Logstash đem tương hỗ không ít loại plugin input không giống nhau khiến cho bạn sinh động trong các công việc nhận mối cung cấp tài liệu log. cũng có thể coi bên trên trên đây : LINK
Filter
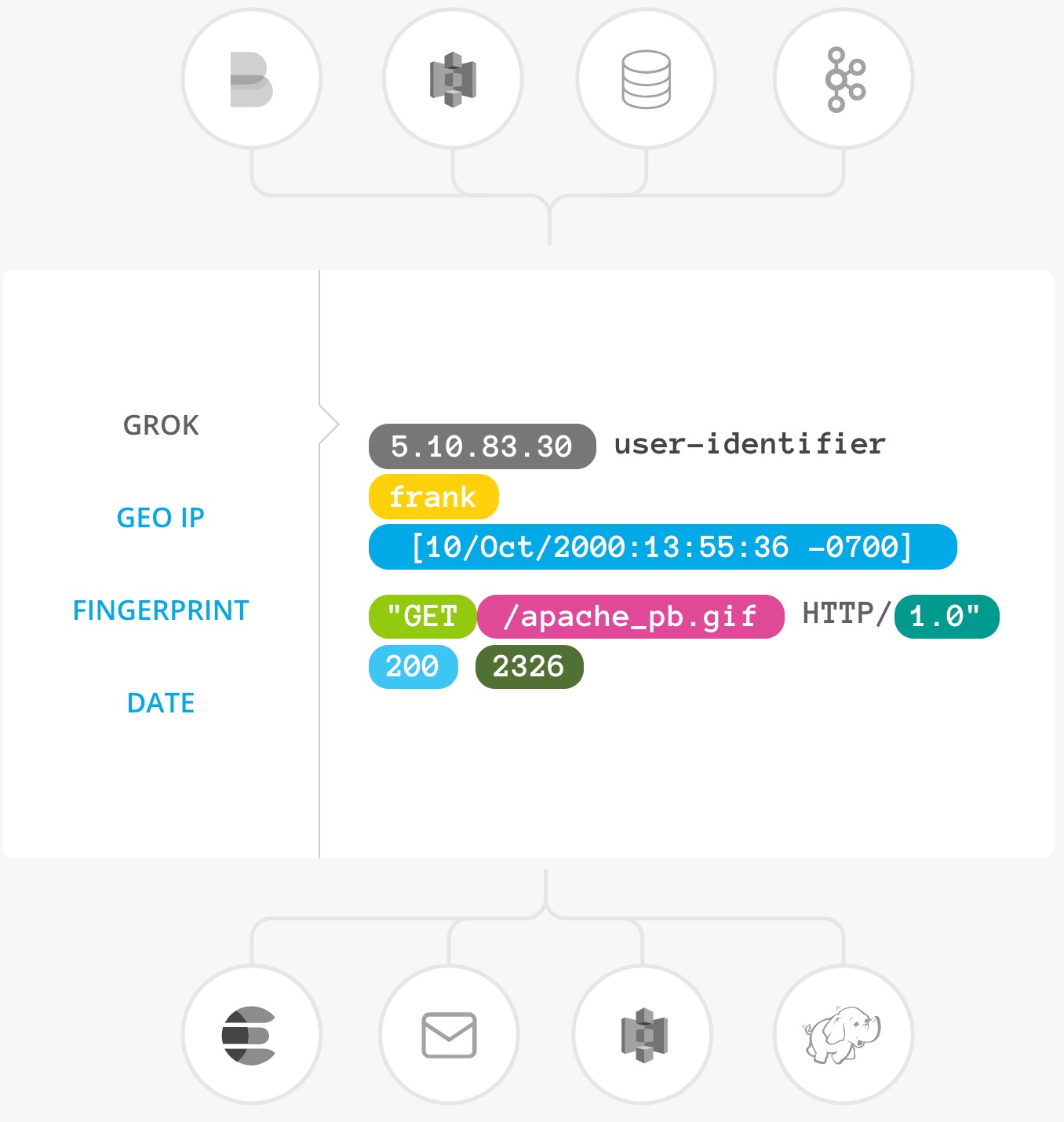
Xem thêm: em chạy không thoát tay anh đâu
Bạn rất có thể phối kết hợp filter với những ĐK đối chiếu nhằm mục đích triển khai 1 tác vụ hành vi (action) Khi một sự khiếu nại thoả mãn khớp với những tiêu chuẩn tự chúng ta được đi ra. Một số filter plugin hữu ích như :
- grok: Nếu chúng ta bắt gặp một tài liệu sự khiếu nại log với cấu tạo văn bạn dạng ko thông dụng hoặc là phức tạp, thì Grok hiện nay là plugin filter tốt nhất có thể nhằm phân tách cú pháp tài liệu log ko được cấu tạo văn bạn dạng trở thành một loại đem cấu tạo và rất có thể truy vấn được.
- mutate: triển khai sự thay cho thay đổi bên trên vấn đề sự khiếu nại log như: thay tên, xoá, thay cho thế, tinh ma chỉnh những ngôi trường (field) vấn đề của việc khiếu nại log.
- drop: ngừng xử lý sự khiếu nại ngay lập tức ngay thức thì, ví dụ những ‘debug event’.
- clone: tạo ra một bạn dạng copy của việc khiếu nại.
- geoip: tăng vấn đề về vùng địa lý của vị trí IP (thường nhằm hiển thị biểu đồ vật bên trên Kibana)
Outputs
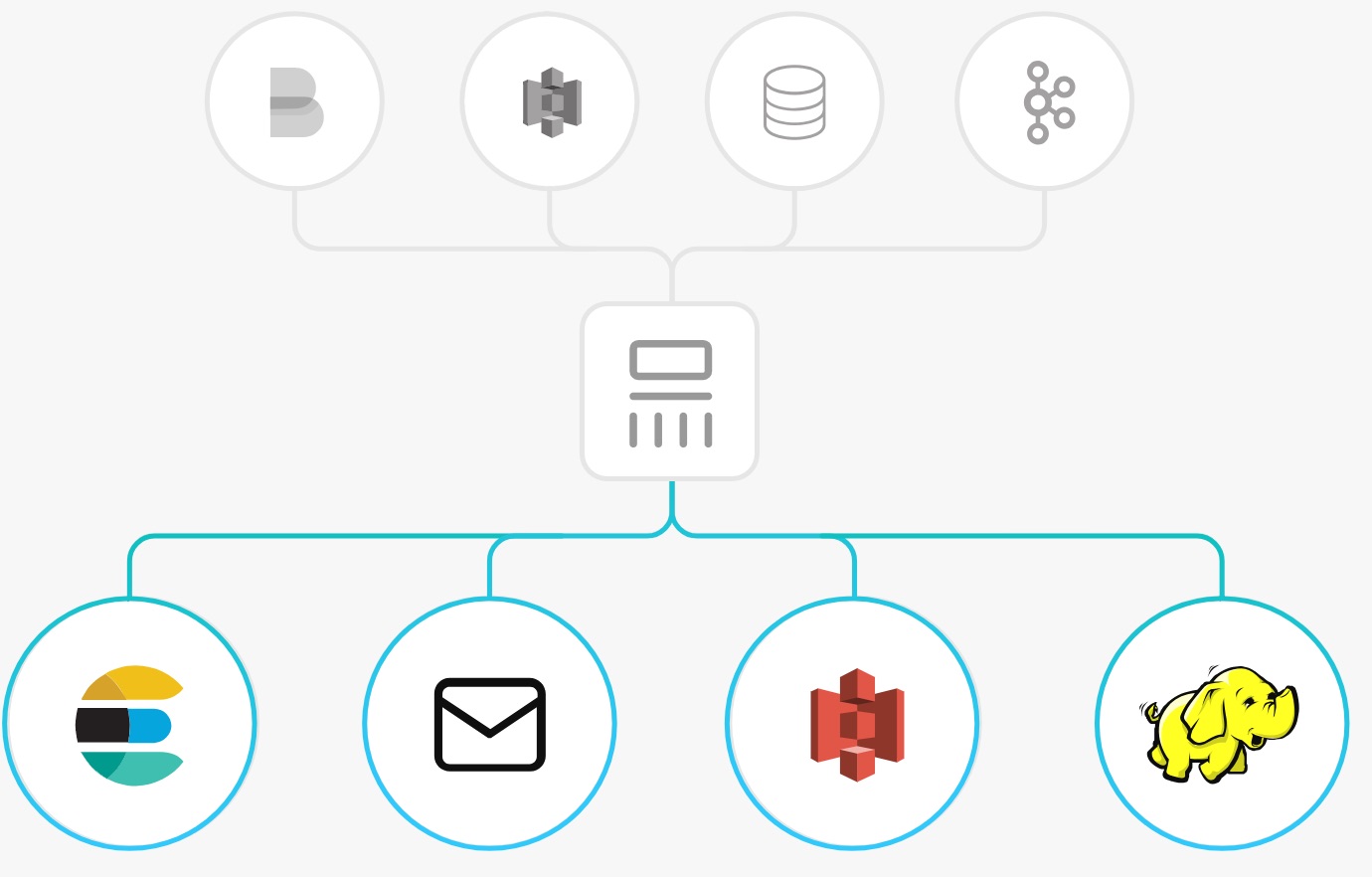
Output là bước ở đầu cuối nhập chuỗi công việc xử lý của Logstash. Một sự khiếu nại rất có thể đem qua không ít output không giống nhau, tiếp đó là những Output plugin hoặc dùng.
- elasticsearch: gửi tài liệu sự khiếu nại cho tới khối hệ thống Elasticsearch. Tất nhiên đầu cuối của khối hệ thống logging ELK thông thường là Elasticsearch khiến cho bạn tàng trữ log, mò mẫm tìm kiếm log, …
- file: nếu như khách hàng chả cần thiết bất kì sự tàng trữ log cho tới việc mò mẫm mò mẫm, hiển thị,… thì rất có thể lưu đi ra tệp tin bên trên khối hệ thống.
- graphite: gửi tài liệu cho tới graphite, một trong mỗi tool mã mối cung cấp hé tương hỗ việc tàng trữ và tạo ra biểu đồ vật metric.
- statsd: gửi tài liệu cho tới công ty ‘statsd’.
Bạn rất có thể tìm hiểu thêm tăng những Output plugin bên trên trên đây : LINK
3. Cấu trúc folder của Logstash
Hiện nhập chuỗi những nội dung bài viết về khối hệ thống Logging ELK, bản thân thông thường thiết đặt Logstash bên trên CentOS 7 kể từ tệp tin rpm . Nên tất cả chúng ta tiếp tục nằm trong điểm qua chuyện cấu tạo folder khoác quyết định của Logstash Khi được thiết đặt kể từ tệp tin .rpm (RHEL/CentOS) hoặc .deb (Ubuntu/Debian).
| Loại | Miêu tả | Đường dẫn folder | Thông số |
| home | /usr/share/logstash | ||
| bin | /usr/share/logstash/bin | ||
| settings | /etc/logstash | ||
| conf | /etc/logstash/conf.d/*.conf | ||
| logs | file log của lịch trình logstash | /var/log/logstash/ | path.logs |
| plugins | /usr/share/logstash/plugins | path.plugins | |
| data | /var/lib/logstash |
4. File thông số kỹ thuật Logstash
Logstash đem 2 loại tệp tin thông số kỹ thuật : pipeline config file dùng làm khái niệm quy trình xử lý log pipeline ; setting file dùng làm thông số kỹ thuật những thông số kỹ thuật tương quan cho tới sinh hoạt và phát động của Logstash.
4.1 Pipeline configuration file
Thư mục chứa chấp thông số kỹ thuật xử lý pipeline bởi vì Logstash nằm ở vị trí folder : /etc/logstash/conf.d/ . Mặc quyết định Logstash tiếp tục chỉ load thông số kỹ thuật của những tệp tin đem đuôi extension là ‘.conf‘
Chúng tớ tiếp tục cút cụ thể phần thông số kỹ thuật pipeline logstash ở bài bác không giống. Nhưng chúng ta cũng có thể biết sơ qua chuyện đó là cấu tạo thông số kỹ thuật cơ bạn dạng của một pipeline logstash xử lý sự khiếu nại data.
input {
stdin {}
tệp tin {}
...
}
filter {
grok {}
date {}
geoip {}
...
}
output {
elasticsearch {}
gmail {}
...
}
4.2 File tinh ma chỉnh công ty Logstash
Các tệp tin thông số kỹ thuật của công ty Logstash nằm ở vị trí folder : /etc/logstash/ . Dưới đó là vài ba tệp tin cơ bạn dạng cần thiết Khi thông số kỹ thuật chạy Logstash.
- logstash.yml : file này chứa chấp những thông số kỹ thuật cộng đồng giành riêng cho công ty Logstash.
- pipelines.yml : file này thông số kỹ thuật folder chạy pipeline, con số pipeline chạy bên cạnh đó, kiểu dáng chạy pipeline,..
- jvm.options : chứa thông số kỹ thuật Java Virtual Machine (JVM). Sử dụng tệp tin này để thay thế thay đổi những thông số kỹ thuật tương quan cho tới heap space, thông thường cần thiết trong các công việc tối ưu hoá công ty logstash.
4.3 Log của Logstash
Nếu chúng ta vận chuyển Logstash theo đuổi ‘.rpm‘ hoặc ‘.deb‘ đã và đang được gói gọn, thì tệp tin log của công ty Logstash nằm ở vị trí : /var/log/logstash/
Nếu chúng ta chỉ tải về logstash source và chạy thì nó nằm ở vị trí folder ứng phát triển thành môi trường: $LS_HOME/logs/
Xem thêm: yêu nhầm chị hai được nhầm em gái
Logstash dùng framework “Log4j 2” nhằm định hình cấu tạo log và xử lý log của riêng biệt công ty Logstash. Logstash tương hỗ một trong những công dụng tương quan log như : Log API, slow-log config, log4j 2 config,…
Tổng kết
Vậy là chúng ta đang được trải qua tổng quan tiền về Logstash và sơ lược cơ hội Logstash sinh hoạt nhập khối hệ thống ELK Stack Logging rồi. Những phần sau tất cả chúng ta tiếp tục nối tiếp cút sâu xa về Logstash nhé.
Nguồn: https://yamada.edu.vn/











Bình luận